Das Problem mit CPU-Overcommitment ist so alt wie die Virtualisierungstechnologie und ist mir in den letzten Jahren häufig bei meiner Arbeit begegnet. Die Fälle häufen sich allerdings, seit die Lizenzkosten eines Hypervisor-Anbieters massiv gestiegen sind.
Die hohen Kosten haben so manche IT-Abteilungen dazu verführt, ihre vorhandene Hardware maximal auszureizen. Das heißt oft: wesentlich mehr virtuelle CPUs pro Host, als physisch vorhanden sind. Ein gewisses Maß an CPU-Overcommitment ist in virtualisierten Umgebungen üblich – doch was passiert, wenn man es übertreibt?
Vor Kurzem durfte ich einen Extremfall von CPU-Overcommitment in einem VMware-Cluster mit 10 ESX-Hosts bearbeiten. Der Kunde betrieb im Cluster nicht nur klassische virtuelle Maschinen, sondern gleichzeitig NSX-T für die Netzwerkvirtualisierung und vSAN für den Storage. Netzwerk, Storage und Compute liefen also auf derselben physischen Plattform – und kämpften damit um dieselben CPU-Ressourcen im Cluster.
Die Probleme begannen schleichend, als aufgrund einer neuen Applikation weitere virtuelle Server im Cluster hinzugefügt wurden. Anfangs schien alles unauffällig, doch die Symptome nahmen über Wochen hinweg zu und wurden zunehmend kritisch, während die eigentliche Ursache zunächst nicht ersichtlich war.
Symptome im zeitlichen Verlauf
Wie die Admins berichteten, traten die Probleme nicht gleichzeitig auf, sondern verstärkten sich im Laufe der Zeit.
1. Langsam werdende Citrix-Systeme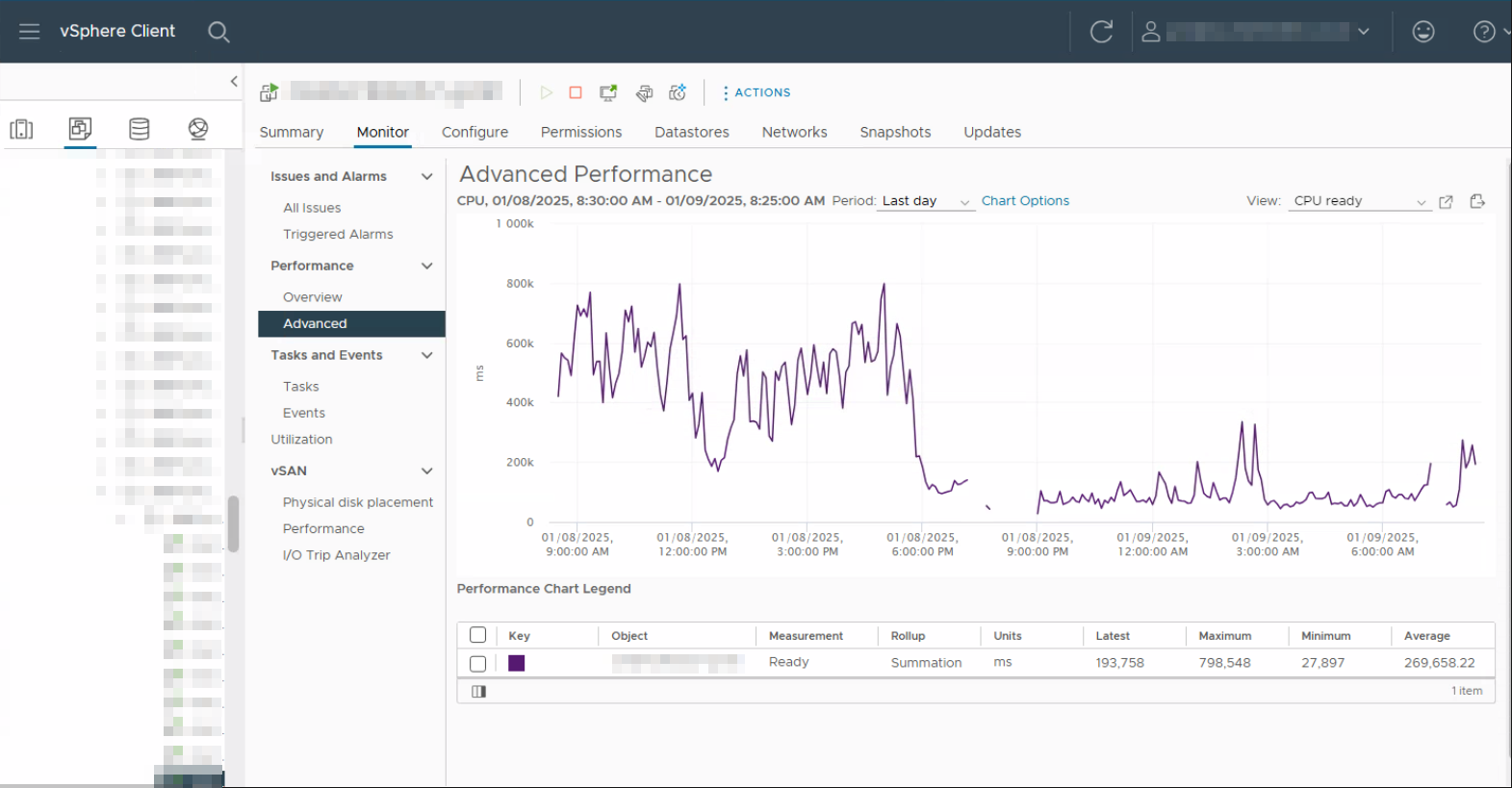
Über mehrere Wochen hinweg meldeten die Fachbereiche, dass die Citrix-Umgebung immer träger wurde.
Logins verzögerten sich, Sitzungen luden nur zögerlich, und allgemeine Anwendungen wirkten zunehmend langsam.
Die Administratoren reagierten pragmatisch, aber falsch:
Sie erhöhten die vCPU der Citrix-Server, in der Hoffnung, damit das Problem zu entschärfen.
2. Datenbanken werden langsam
Kurz darauf zeigten sich ähnliche Symptome bei den Datenbanken.
Reports dauerten länger, Abfragen reagierten verzögert, und die Performance der Business-Applikationen ging bergab.
Erneut entschied man sich für denselben Ansatz:
zusätzliche vCPUs für die betroffenen Datenbank-VMs.
3. Instabile VPN-Verbindungen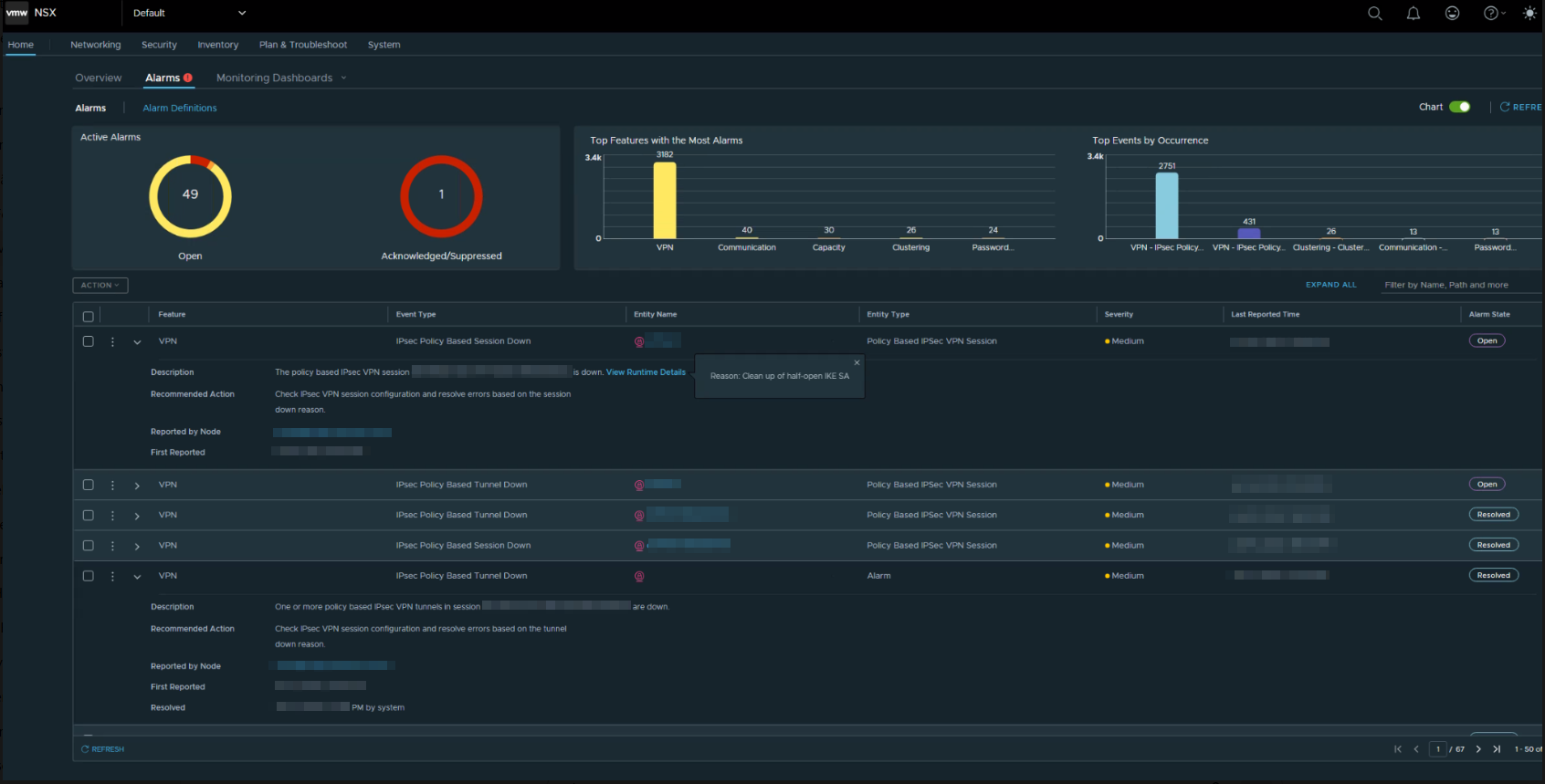
Mit zunehmender CPU-Belastung eskalierten die Probleme deutlicher.
Im Verlauf kam es zu sporadischen VPN-Unterbrüchen zwischen den Standorten. Die über NSX-T betriebenen IPsec-Tunnel flappten oder brachen ab.
Da diese Symptome klassisch nach Netzwerkfehlern aussehen, suchte man zunächst in Routing, Firewall, VPN-Gegenstellen und den NSX-T-Control-Plane – allerdings ohne Erfolg.
4. vSAN mit hohen Latenzen und fehlgeschlagene Backups
Schließlich meldete auch vSAN Warnungen:
Latenzspitzen, verzögerte Replikationen und hohe Latenzen.
Parallel dazu liefen Veeam-Backups nicht mehr zuverlässig.
Backup-Jobs liefen unvollständig oder blockierten sich gegenseitig, da die Backup-VMs ebenfalls zu wenig CPU-Zeit erhielten.
DRS konnte ebenfalls nicht mehr sinnvoll eingreifen, da die Hosts durch das Overcommitment gleichmäßig stark belastet waren und kaum noch Ausweichkapazitäten boten.
Overcommitment außer Kontrolle: Ursache und Eskalation
Die anschließende Analyse mit ESX-TOP offenbarte ein klares Bild:
Der Cluster war massiv überbucht. Die Summe aller zugewiesenen vCPU im Cluster lag mit einem Verhältnis von 1:10 deutlich über der Anzahl verfügbarer physischer Kerne.
Hinzu kam eine ungünstige vCPU-Konfiguration vieler virtueller Maschinen:
Viele VMs waren mit mehreren virtuellen Sockets, aber nur einer vCPU pro Socket konfiguriert (z. B. 4 vSockets mit je 1 vCPU). Auf Hosts mit zwei physischen CPU-Sockets und je 20 Kernen pro CPU erzeugt diese Konstellation unnötigen Druck auf den ESXi-Scheduler und wirkt sich spürbar negativ auf die Performance aus.
Neben den ohnehin hohen CPU-Ready-Zeiten traten auch Co-Stop Probleme deutlich auf. In einem überbuchten Cluster findet der ESXi-CPU-Scheduler immer seltener freie physische Kerne um alle vCPU der VM zum gleichen Zeitpunkt zu schedulen. Dadurch müssen einzelne vCPUs warten, bis alle wieder einen gemeinsamen Zeitslot haben. Je mehr vCPU einer VM zugewiesen sind, desto geringer ist die Chance für die VM eine einen gemeinsamen Slot zu finden.
Das führt dazu, dass die VM intern ins Stocken gerät – obwohl rein rechnerisch noch CPU-Kapazität vorhanden wäre. Besonders betroffen waren Systeme, Citrix-Server, vCenter und NSX-T-Edge-Nodes, die stark auf gleichmäßige CPU-Zeit angewiesen sind.
Die Folgen:
- deutlich erhöhte CPU-Ready-Zeiten bei allen VM
- zusätzliche Co-Stop-Verzögerungen durch fehlende parallele Ausführungsfenster. Besonders bei allen VM mit sehr vielen vCPU
- Die DPDK-Worker-Threads des NSX-T hatte zu wenig CPU-Ressourcen
Durch die ständige Erhöhung der vCPU durch die Admins geriet der Cluster schließlich vollständig ins Straucheln. Jede weitere vCPU verschärfte die Engpässe. Kritische Prozesse, darunter NSX-T Edge-Services, vSAN-Operationen und selbst das vCenter liefen teils nur noch mit einem Bruchteil ihrer notwendigen CPU-Zeit.
Die Kaskade war unübersehbar:
- NSX-T VPN Unterbrüche zu den Standorten, weil rechenintensive Verschlüsselungsprozesse keine CPU-Ressourcen hatten
- vSAN konnte Daten nicht schnell genug replizieren und hatte hohe Latenzen
- vCenter DRS war am Anschlag und hat wild die VMs verschoben
- Veeam Backup Jobs sind fehlgeschlagen
Problemlösung:
Die Lösung des Problems bestand nicht darin zunächst mehr Hardware zu integrieren. In diesem Fall führten folgende Massnahmen zum Ziel:
- Es wurde bei den meisten VMs die Socket Konfiguration auf eins gesetzt.
- Nur bei VMs die explizit von 2 Sockets profitieren, wurden auch mit 2 Sockets konfiguriert
- Den VMs wurde zunächst konsequent nur 1-2vCPU zugewiesen. Dieser Wert wurde später ggf. korrigiert wenn es notwendig war. Die meisten VMs funktionierten tadellos mit dieser Minimalausstattung
Diese Massnahmen haben den gesamten Cluster wieder stabilisiert. Letztendlich war der Cluster zwar sehr stark ausgebucht, in den kritischen Zustand ist der Cluster aber erst durch die falsche CPU Konfiguration der VMs in der Vergangenheit gekommen.
Fazit:
1. Weniger ist oft mehr
Dieser Vorfall zeigt eindrücklich, wie schnell sich übertriebenes Overcommitment und eine ungeeignete CPU-Konfiguration zu einem flächendeckenden Problem entwickeln können – besonders in Umgebungen, in denen Compute-, Netzwerk- und Storage-Virtualisierung auf derselben physischen Infrastruktur laufen.
Die wichtigste Erkenntnis: Mehr vCPUs bedeuten nicht automatisch mehr Leistung. Nur wenige Applikationen profitieren von mehreren Sockets
Unabhängig vom genutzten Hypervisor ist es wichtig, die virtuellen Systeme auf die verfügbaren physischen Hardwareressourcen genau abzustimmen.
Es ist sinnvoll, die vCPU-Konfiguration pro VM zu prüfen. Auch wenn der physische Host beispielsweise über zwei CPU-Sockets verfügt, ist es nicht sinnvoll, jeder VM ebenfalls zwei Sockets zuzuweisen. Manche VM-Typen bzw. Applikationen profitieren von mehreren Sockets, die meisten jedoch nicht. In überbuchten Umgebungen kann der ESXi-CPU-Scheduler dann oft nicht genügend freie physische Kerne finden, um alle vCPUs effizient zu betreiben.
Jede Applikation, die innerhalb einer VM ausgeführt wird, sollte darauf geprüft werden, ob sie tatsächlich mehrere parallele Threads nutzen kann und somit von mehreren vCPUs profitiert.
Wenn die Ressourcen bereits knapp sind, könnte es eine Option sein, alle VMs in Bezug auf die optimale CPU Konfiguration zu analysieren. Erfahrungsgemäss können die durch CPU Overcommitment verursachten Performanceprobleme bereits gelöst werden, in dem man falsche vCPU und Socket Konfigurationen korrigiert.
2. Trennung der Management Appliances
Es empfiehlt sich, die Management-VMs entweder in einem eigenen Ressourcenpool zu betreiben oder mittels Affinity-Regeln an dedizierte Hosts zu binden. Dadurch bleiben die zentralen Management-Systeme funktionsfähig, selbst wenn die restliche Umgebung von Ressourcenengpässen betroffen ist.
Der Fall zeigt: Nicht nur das Hinzufügen von Ressourcen löst die Probleme, sondern eine saubere, zur Hardware passende CPU-Konfiguration der virtuellen Maschinen und der Applikationen und Services innerhalb.